** 原文链接:DeepMind**
** 翻译:MatrixC7,一定程度上借用了 Google 翻译 **
几十年来,游戏一直被用作测试和评估人工智能系统性能表现的重要方法。 随着能力的提高,研究界开始寻求更复杂的游戏 —— 这些游戏拥有可以用来解决科学和现实问题所需的多种智能要素。近年来,最具挑战性的即时战略游戏(RTS)之一,也是有史以来最长寿的电子竞技项目之一,星际争霸,已公认成为人工智能研究中的一项 “大挑战”。
现在,让我们来介绍我们的 星际争霸 II 程序 ——AlphaStar。这是第一个打败顶级职业选手的人工智能。在 2018 年 12 月 19 日举行的一系列测试赛中,AlphaStar 首先取得了由 Dario “TLO“ Wünsch 迎战的基准测试比赛的胜利,随后利落地以 5 比 0 击败了来自 Team Liquid 的 Grzegorz “MaNa“ Komincz,世界上最强的职业星际争霸选手之一 。比赛全部于 天梯地图、专业比赛条件下进行,其中没有任何特殊游戏限制。
尽管在 雅达利 、 超级马里奥 、 雷神之锤 III 竞技场的夺旗模式 和 Dota 2 等游戏方面取得了重大成功,但直到现在,AI 技术在星际争霸的复杂性仍显得力有不逮。在手动修改游戏的主要因素、对游戏规则施加重大限制、赋予系统超人能力、或是在简化地图上进行游戏时,AI 才完成了 最好的发挥 。但即使进行了这些修改,也没有任何系统可以与职业玩家的技巧相媲美。 相比之下,AlphaStar 使用一种深度神经网络来完整地游玩星际争霸 II。这种神经网络在 监督学习 和 强化学习 两种方式下,直接使用原生游戏数据进行训练。
星际争霸带来的挑战
由 暴雪娱乐公司 制作的星际争霸 II 是在一个设置在虚构的科幻世界中的、拥有具有丰富的多层次游戏玩法的、旨在挑战人类的智慧的游戏。自星际争霸诞生,它已经成为历史上规模最大、最成功的游戏之一,并拥有超过 20 年的电子竞技历史。
星际争霸中有几种不同的模式,但在电子竞技中最常见的还是 1v1 的五局胜负制。每位选手需要在 “虫族”、”神族”、”人族” 的三个种族中选取一族开始比赛。这三个种族各有不同的特点与能力(虽然职业选手通常只会专精一族)。每个玩家都从一定数量的农民开局。农民能够收集基本资源以建造更多单位和建筑,并且研发新的技术。因此这将会要求玩家通过收集其他地区的资源、建造更多的复杂建筑、研发更多的技能来智胜对手。为了取得胜利,宏观上玩家必须仔细均衡经济的大局管理,而微观上玩家则需要操控每一个不同的单位。
平衡短期和长期目标、适应意外情况发生的需求对于经常表现出脆弱和不灵活的系统提出了巨大的挑战。解决这个问题需要在以下几个 AI 研究项目中取得突破:
- 博弈论:星际争霸就像是石头剪刀布,并不存在一种完美的策略。因此,AI 训练需要不断探索并拓展策略(战术)方向的知识。
- 信息不完善:不像是国际象棋或是围棋,玩家们可以见到任何事物。在星际争霸中,重要的信息被隐藏起来。它需要选手们积极地进行探索才能发现。
- 长期规划:像许多现实世界的问题一样,因和果之间不是瞬间完成的。游戏可能需要长达一个小时才能完成。这意味着游戏早期采取的行动可能在很长一段时间内无法获得回报。
- 实时:与传统棋盘游戏不同,玩家轮流进行棋子移动,星际争霸玩家必须在游戏进行时不间断执行操作。
- 大操作空间:几百个不同的单位和建筑必须瞬间被操控,从而形成一个实时的、拥有各种可能性的组合空间。在这基础之上,操作可以进行分级,并可以被修改和扩充。我们对游戏的参数化使得在每一个时间长中,能够完成平均大约 10 到 26 个有效操作。
由于这些艰涩挑战的存在,星际争霸成为了 AI 研究的一项 “大挑战”。自 2009 年 the BroodWar API 的启动以来,星际争霸和星际争霸 2 中正在进行的比赛已经有了一些进展。这些比赛包括 AIIDE StarCraft AI Competition、CIG StarCraft Competition、Student StarCraft AI Tournament, 和 Starcraft II AI Ladder。为了帮助他们走得更远,我们在 2016 年和 2017 年和暴雪合作,公开了一套名为 “PySC2“ 的开源工具。这套工具中包括了自公布以来最多的匿名玩家 replay。我们现在已经在这项工作的基础上,结合工程和算法上的突破来制造 AlphaStar。
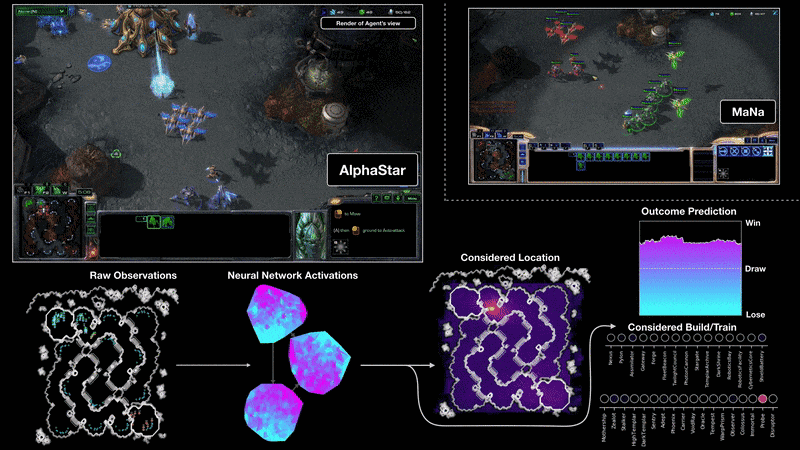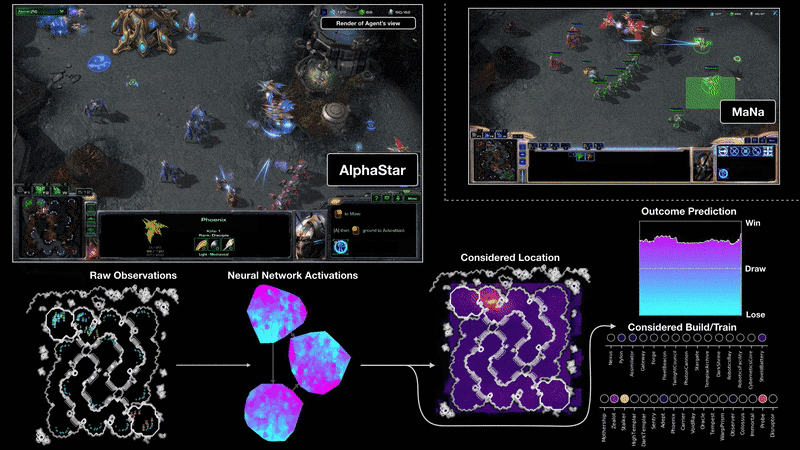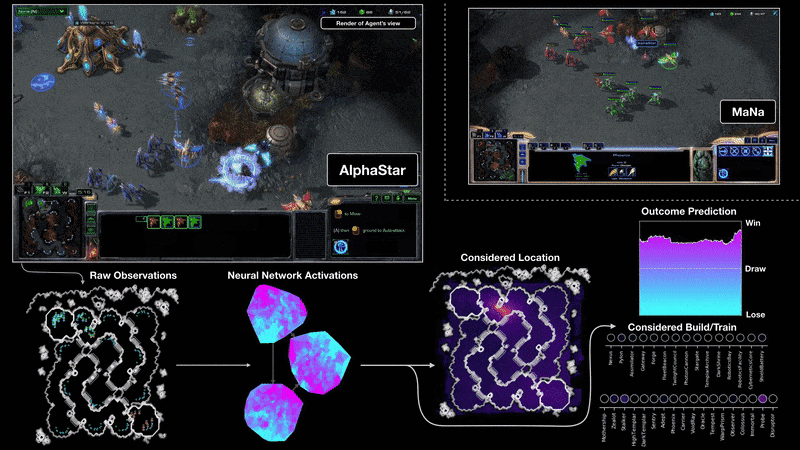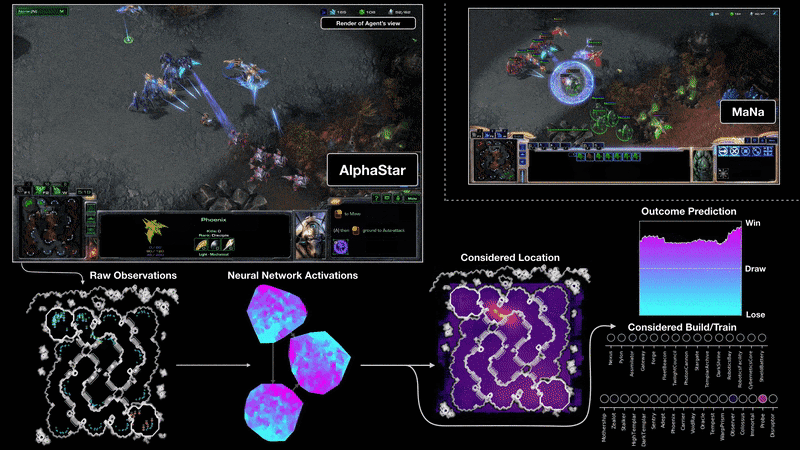
上图为和 MaNa 的两场比赛中,将 AlphaStar 可视化后的视角。图中展示了 AlphaStar 眼中的游戏:输入至神经网络的原生观察数据、精神网络的内部激活、一些在被考虑中的举措(例如点击某处、建造某物)和预测结果。图中也展示了 MaNa 的游戏视角,虽然它并不能被 AlphaStar 分析。
AlphaStar 是如何被训练的
AlphaStar 的操作由一个深度 神经网络 生成。神经网络收集来自原生游戏界面(部队单位与他们的属性)的输入信息,输出能在游戏中组成一次行动的一连串指令。更具体来说,神经网络架构将单位放入 变压器 ,同时将其与一个 深度长短期记忆模型核心 、一个具有 指针网络 的 自回归策略头 和一个 集中值基线 相结合。 我们相信这种先进的模型将有助于机器学习研究中的许多需要用到长期序列建模和大输出空间的其他挑战。比如翻译、语言建模和视觉表示。
AlphaStar 还使用了一种新颖的多智能体学习算法。 神经网络最初是通过 暴雪发布的匿名的、面向人类的游戏,在监督学习的方式下训练的。 这使 AlphaStar 能够通过模仿学习星际争霸阶梯上玩家使用的基础微宏观策略。 最初的智能体在 95%的比赛中击败了内置的 “精英” 级 AI—— 相当于一个人类玩家的黄金级别左右水平。

AlphaStar 联赛。智能体们最初通过人类玩家的 replay 进行训练,然后和联赛中的其他智能体进行训练。在每次循环中,新的参赛者从原来的竞争者中分支出来,而原来的参赛者被冻结。同时可以调整确定每个可能已经适应的智能体的学习目标的匹配概率和超参数,从而在保持多样性的同时增加难度。通过从参赛者的游戏结果中加强学习来更新代理的参数。 最终的智能体从联赛的纳什分布中抽样选出(无需替换)。
随后,将上述应用于培养多智能体的强化学习过程。一个连续的联赛得以建立。联赛中的智能体,也就是参赛者,相互对抗,类似于人类通过在 星际争霸天梯 上进行排位来进行星际争霸。在现有参赛者的分支下,联赛中新的参赛对手变得越来越多;每个智能体都会从对抗中学习。这种新形式的训练进一步采用了 基于人口的强化学习 的思想,创造了一个不断探索星际争霸巨大策略空间的游戏过程,同时确保每个参赛者在策略战中表现出色,并且不忘记如何击败前者。
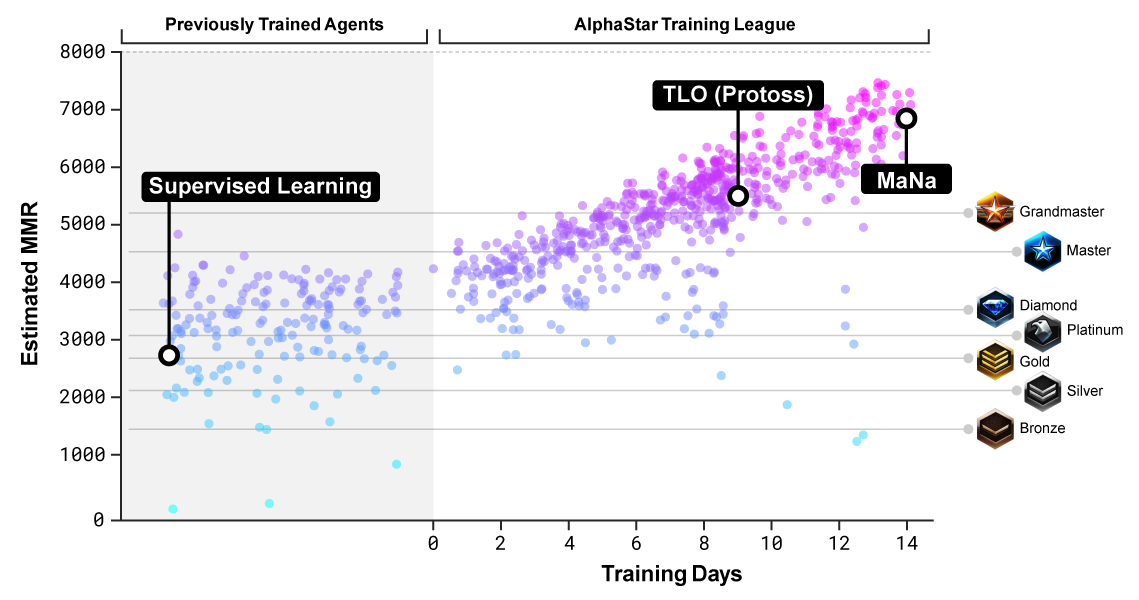
MMR(比赛匹配分级)是一个衡量玩家技巧的大致估计。上图是在整个训练中,和暴雪的在线联赛相比,对 AlphaStar 内的参赛者的 MMR 估计。
随着联赛的进行和新的参赛者的创建,出现了能够击败早期战术的新对抗战术。有一些新的参赛者执行的战术仅仅是对先前战术的改进,但有其他参赛者发现了全新的战术,包括全新的建造顺序,单位构成和微观管理。例如,在早期的 AlphaStar 联赛中,”廉价” 的战术,比如 光子炮 rush 或者 隐刀 rush 总是很受欢迎。随着训练的进行,这些风险性的战术被放弃,其他战术得到了开发:比如,通过在单矿上补比 16 个更多的农民来运营,或用两个 先知 来骚扰对手的农民和经济。这一过程正是类似于玩家发现新战术的过程,并且能够击败先前为人偏爱的方法。自星际争霸发布以来一直如此。
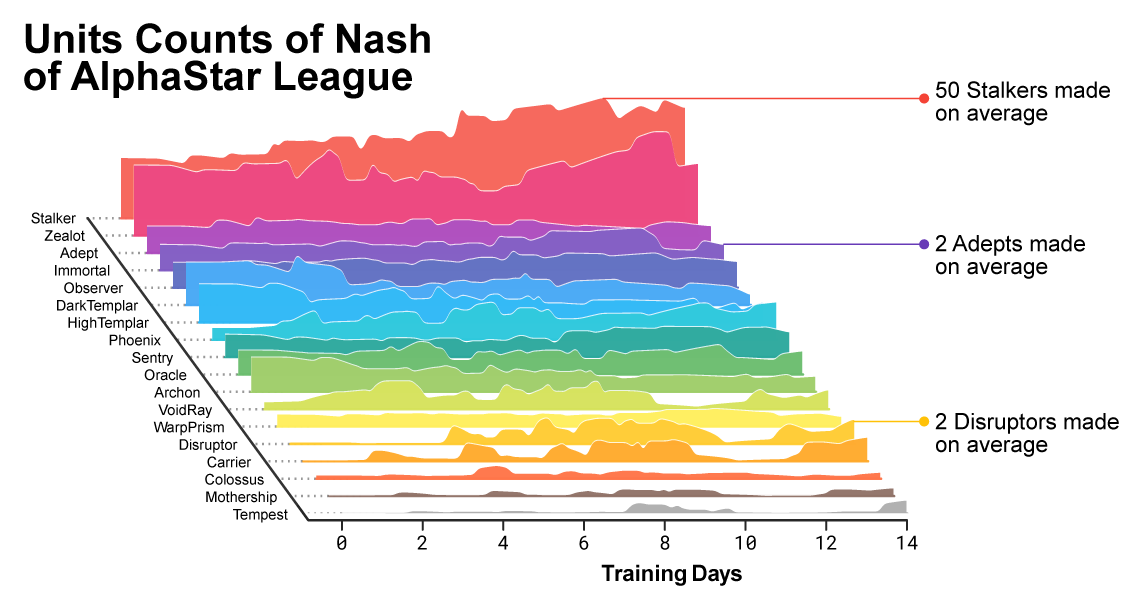
随着训练的进行,创造 AlphaStar 的联赛逐渐改变了出兵方式
为了激发联赛中的多样性,每个智能体都有自己的学习目标:例如,这个智能体应该打败哪些智能体。同时,每个智能体也有影响其发挥的其他内部因素。这个智能体的目标可能是击败某一个特定的参赛者,而另一个智能体可能必须击败整个参赛者的分布,但是可以通过建造更多的特定单元来实现这一目标。这些学习目标在训练期间都在进行调整。
此处请参考原网站。原网站中列出了不同智能体的 MMR 与出兵分布和可能性
展现了 AlphaStar 联赛中参赛者的可交互式可视化视图。和 TLO、MaNa 对战的智能体已特别注明。
通过参赛者游戏中的相互对抗式的强化学习,每个智能体的神经网络权重得到更新以便优化其个人学习目标。权重更新规则是一种新颖并且有效的 离线策略、演员 - 评判家 强化学习算法,并且辅有 经验重放 , 自我模仿学习 和 策略蒸馏。

该图显示了最后被选出与 MaNa 竞争的智能体(黑点)是如何在训练过程中改变其战术和参赛者(彩色圆点)的。每个点都代表 AlphaStar 联赛中的参赛者。点的位置表示其策略(内部下方插图),点的大小表示在训练期间被选择作为和 MaNa 对战的智能体的对手的频率。
为了训练 AlphaStar,我们使用 Google 的 v3 TPU 构建了一个高度可扩展的分布式训练设备。它能支持智能体们从数万个星际争霸 II 的并行实例中学习。AlphaStar 联赛运行了 14 天,每一个智能体使用了 16 个 TPU。在这 14 天的训练中,每个智能体都经历了最高 200 年的实时星际争霸游戏时间。最终的 AlphaStar 智能体由 联赛的纳什分布 的组件构成 —— 换句话说,最有效的策略组合已经被找到了。这个智能体只需要一个桌面型 GPU 即可运行。
我们正在准备这项工作的全面的技术描述,以便在同行评审期刊上发表。
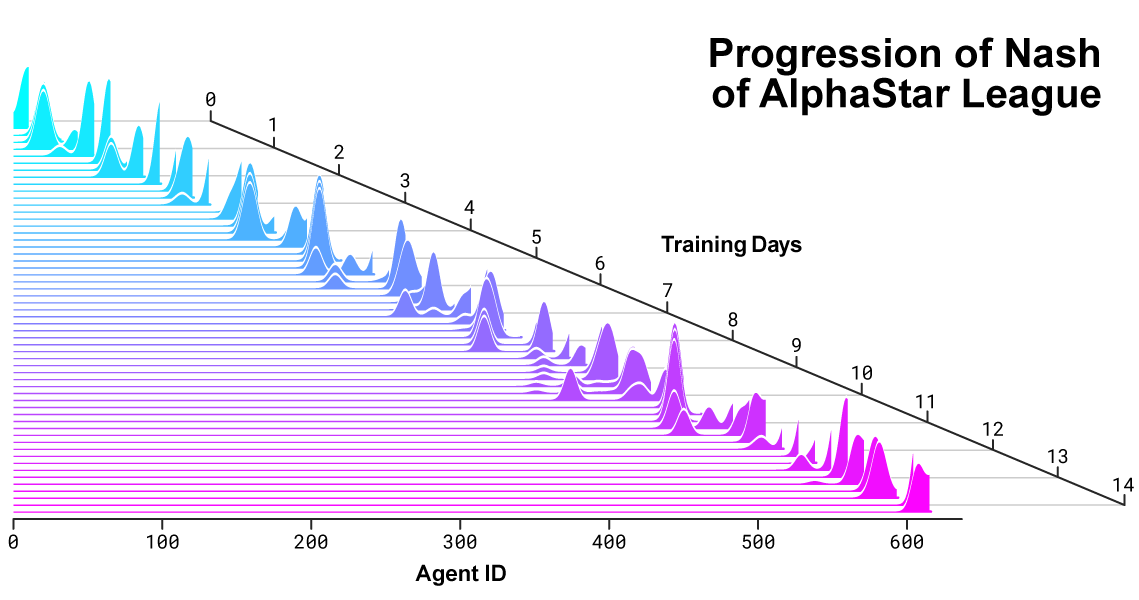
上图为随着 AlphaStar 联赛的发展和新的参赛者的出现,参赛者之间的纳什分布变化。作为互补型参赛者的可利用程度最小的纳什分布,对最新参赛者的评价最高,展示了对所有先前参赛者的持续进步。
AlphaStar 是如何观察和玩星际争霸的
职业的星际争霸选手能够达到数百的平均 APM,例如 TLO 和 MaNa。这个数字要远远小于大部分 现存的机器人。机器人可以独立控制每个单位并且持续性维持数千甚至数万的 APM。
在和 TLO、MaNa 的比赛中,AlphaStar 达到了 280 左右的平均 APM。虽然它的操作可能会更精准,但这明显低于职业选手的平均 APM。这个较低的 APM 的原因是 AlphaStar 使用 replay 开始训练,因此模仿了人类玩游戏的方式。此外,AlphaStar 在观察和行动之间有平均 350 毫秒的延迟。
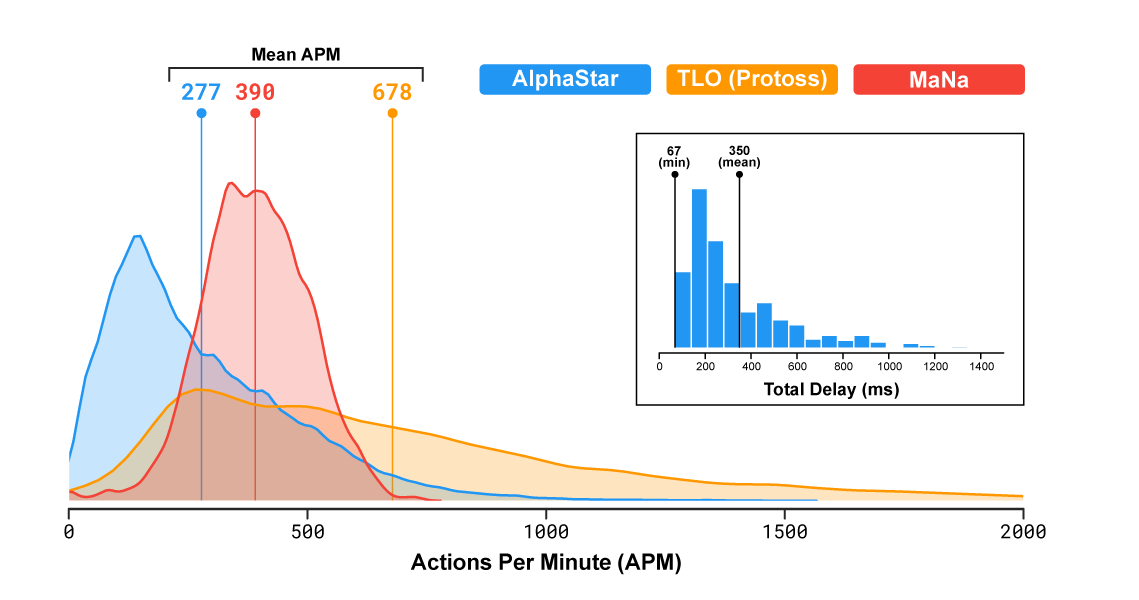
AlphaStar、TLO 和 MaNa 的 APM 分布,以及 AlphaStar 在观察和行动之间的延迟分布。
在和 TLO、MaNa 的比赛中,AlphaStar 通过其原生界面直接和星际争霸的游戏引擎进行交互,这意味着 AlphaStar 可以直接在地图上看到自己的信息属性以及对手的可见单位,而无需移动画面 —— 相当于在缩小画面的情况下玩游戏。与之相对,人类玩家必须要明确运营 “注意力经济”,从而决定到底要把画面移到何处。但是,对 AlphaStar 游戏的分析表明,AlphaStar 有在隐秘地管理着注意力的焦点。平均而言,智能体每分钟 “环境切换” 约 30 次,和 MaNa、TLO 类似。
另外,在比赛之后,我们开发了第二版 AlphaStar。与人类玩家一样,这个版本的 AlphaStar 需要选择什么时候移动画面到什么地方,它只能获取屏幕上的信息,并且只能在可视区域进行操作。
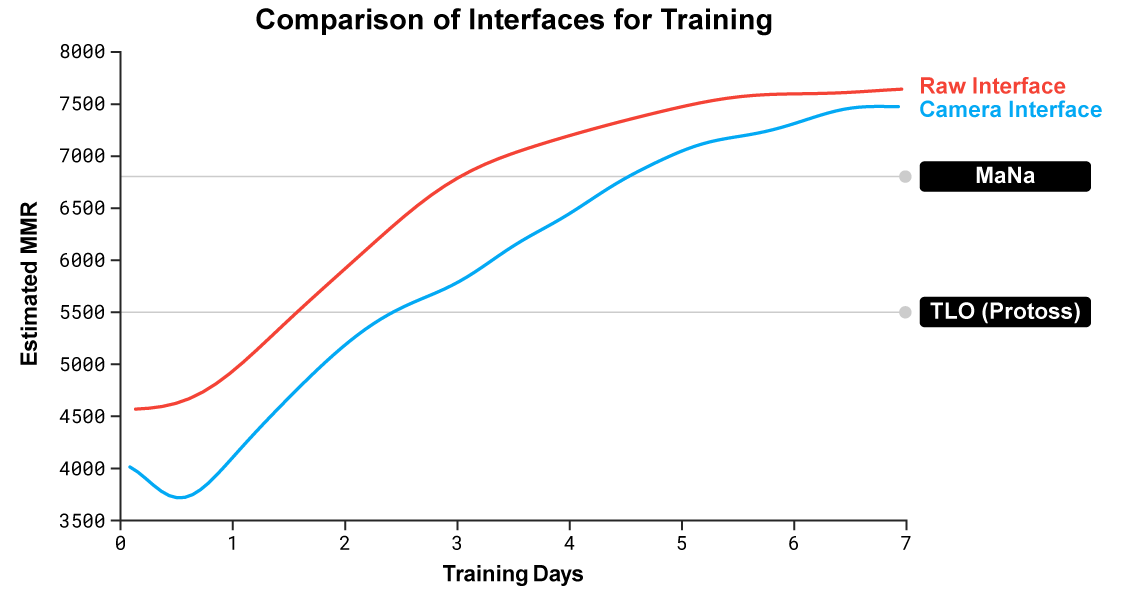
使用原生界面和使用屏幕界面的 AlphaStar 表现。使用屏幕界面的 AlphaStar 很快就赶上了并且和使用原生界面的表现几乎相同。
我们训练了两个新的智能体参加 AlphaStar 联赛,其中一个使用原生界面而另一个必须学会控制屏幕。每个智能体一开始都使用来自人类数据的监管学习训练,随后便进行上文描述过的强化学习。使用屏幕界面的 AlphaStar 基本和使用原生界面的一样强,都在内部的排行榜中超过了 7000 的 MMR。在直播的比赛中,MaNa 打败了使用屏幕界面的 AlphaStar 的、只训练了 7 天的原型机。我们希望在不久的将来能够评估完全训练过的、使用屏幕界面的 AlphaStar。
在和职业选手的交锋中评估 AlphaStar
星际争霸允许玩家在人族、虫族和神族中选择一个种族。我们选择让 AlphaStar 暂时只专攻一族 —— 神族,从而在报告我们内部联赛的结果时,减少训练时间和差异。注意,相同的训练过程可以被应用于任何一个种族。我们的智能机被训练为:星际争霸 2(版本 4.6.2)、神族对抗神族、汇龙岛(Catalyst)。为了评价 AlphaStar 的表现,我们首先让智能机和 TLO(顶级虫族选手、大师级神族选手)对抗。AlphaStar 以 5:0 赢下比赛,使用了各种兵种和建造指令。”我很惊讶智能机的强度,” 他说,”AlphaStar 使用了知名的战术并用了起来。智能机展示了我之前没有想到过的战术,这意味着对于这款我们仍然没有完全探索到底的游戏,可能依旧有新的玩法。”
在我们训练智能机们又一个星期之后,我们和 MaNa 进行了对战。他是世界上最强的职业星际争霸 2 选手之一,并且是最强的 10 位神族选手之一。AlphaStar 再次以 5:0 赢下比赛,展示出了强大的微观和宏观的战术技巧。”AlphaStar 用了我没有预料到的、非常人类的游戏方式,几乎在每场比赛中都完成了进阶的操作和不同的战术,这让我印象很深刻。” 他说,”我已经意识到我的打法在多大程度上依赖于强迫性犯错和能够利用人类反应速度,所以对我来说,这让游戏变成了一束全新的光。我们很期待接下来会发生什么。”
AlphaStar 和其他复杂的问题
星际争霸只是一款游戏,虽然是一个复杂的游戏,我们认为 AlphaStar 背后的这些技术能够在解决其他问题上发挥用处。例如,它的神经网络架构能够对很长时间的可能行为进行建模。游戏通常持续长达一个小时,伴随着成千上万次的移动 —— 基于不完善的信息之下。星际争霸的每一帧都会被用作一步输入,而在游戏剩余部分的每帧之后,神经网络都会依此预测期望的行动顺序。 在很长的数据列上进行复杂预测的基本问题出现在许多现实世界的挑战中,例如天气预报,气候建模,语言理解等等。 通过 AlphaStar 项目内的学习和发展的使用,在之前这些领域取得重大进展的潜力让我们感到非常兴奋。
我们也认为,在安全可靠的 AI 研究方面,我们的某些训练方法也会有用。人工智能面临的一大挑战是系统出错的各种方式,而星际争霸职业选手之前就已经发现,通过找到引发这些错误的创造性方法,很容易击败人工智能系统。AlphaStar 创造性的联赛机制训练过程中,我们找到了最可靠而最不可能出错的方法。而这种方法有潜力能提高通常 AI 系统的安全可靠性,让我们感到很兴奋。特别是在安全十分重要的能源方面,对于解决复杂的边缘情况是有必要的。
达到星际争霸的最高水平代表了在有史以来最复杂的游戏之一的一项重大突破。我们相信这些进步,以及 AlphaZero 和 AlphaFold 等项目最近的进展,代表着我们创建智能系统的使命向前迈出了一步,有朝一日,智能系统将帮助我们为世界上一些最重要和最基本的科学问题展现出新颖的解决方案。
- 感谢 Team Liquid 的 TLO 和 MaNa 的支持和卓越技巧。感谢暴雪以及星际争霸社群的持续协助,使得这项工作得以实现。*
AlphaStar 小组:
Oriol Vinyals, Igor Babuschkin, Junyoung Chung, Michael Mathieu, Max Jaderberg, Wojtek Czarnecki, Andrew Dudzik, Aja Huang, Petko Georgiev, Richard Powell, Timo Ewalds, Dan Horgan, Manuel Kroiss, Ivo Danihelka, John Agapiou, Junhyuk Oh, Valentin Dalibard, David Choi, Laurent Sifre, Yury Sulsky, Sasha Vezhnevets, James Molloy, Trevor Cai, David Budden, Tom Paine, Caglar Gulcehre, Ziyu Wang, Tobias Pfaff, Toby Pohlen, Dani Yogatama, Julia Cohen, Katrina McKinney, Oliver Smith, Tom Schaul, Timothy Lillicrap, Chris Apps, Koray Kavukcuoglu, Demis Hassabis, David Silver
致谢:
*Ali Razavi, Daniel Toyama, David Balduzzi, Doug Fritz, Eser Aygün, Florian Strub, Guillaume Alain, Haoran Tang, Jaume Sanchez, Jonathan Fildes, Julian Schrittwieser, Justin Novosad, Karen Simonyan, Karol Kurach, Philippe Hamel, Ricardo Barreira, Scott Reed, Sergey Bartunov, Shibl Mourad, Steve Gaffney, Thomas Hubert, Yuhuai Wu, 创造 PySC2 的小组 以及整个 DeepMind 小组,特别感谢 RPT, comms and events 小组 *
个人的最后要点式概括
- 训练 AlphaStar 时,研究人员设计了一个 AlphaStar 联赛,类似于天梯,其中所有的参赛者都是 AlphaStar 的智能体(agent)。
- 早期 AlphaStar 中,狗招比如光子炮 rush 或者隐刀 rush 很受欢迎,但之后这些战术因风险性过高被抛弃。
- AlphaStar 逐渐开发了新的战术,比如通过在单矿上补比 16 个更多的农民来运营,或用两个先知来骚扰对手的农民和经济。
- 随着训练的进行,AlphaStar 的智能体们在联赛中逐渐改变着出兵方式。
- AlphaStar 联赛一共运行了 14 天,在这 14 天的训练中,每个智能体都经历了最高 200 年的实时星际争霸游戏时间。
- 在和 TLO、MaNa 的比赛中,AlphaStar 达到了 280 左右的平均 APM。虽然它的操作可能会更精准,但这明显低于职业选手的平均 APM。这个较低的 APM 的原因是 AlphaStar 使用 replay 开始训练,因此模仿了人类玩游戏的方式。
- AlphaStar 在观察和行动之间有平均 350 毫秒的延迟。整个延迟近似一个正偏的二项分布,最低为 67ms,350ms 只是一个平均值。
- AlphaStar 和 TLO 的比赛与 AlphaStar 和 MaNa 的比赛之间相隔了一周,但都发生在 2018 年 12 月。
- 在和 AlphaStar 的比赛中,TLO、MaNa 面对的智能体是互不相同的。即,第一场的 0-5 中,TLO 对抗的是 5 个不同的、训练了 7 天的、原生界面的 AlphaStar 智能体;第二场的 0-5 中,MaNa 与 5 个不同的、训练了 14 天、原生界面的 AlphaStar 智能体。
- 在和 TLO、MaNa 的比赛中,AlphaStar 通过其原生界面直接和星际争霸的游戏引擎进行交互,这意味着 AlphaStar 可以直接在地图上看到自己的信息属性以及对手的可见单位,而无需移动画面 —— 相当于在缩小画面的情况下玩游戏。
- 在 2018 年 12 月比赛之后,我们开发了第二版 AlphaStar。与人类玩家一样,这个版本的 AlphaStar 需要选择什么时候移动画面到什么地方,它只能获取屏幕上的信息,并且只能在可视区域进行操作。
- 使用原生界面和使用屏幕界面的 AlphaStar 表现。使用屏幕界面的 AlphaStar 很快就赶上了并且几乎和使用原生界面的表现相同,都在内部的排行榜中超过了 7000 的 MMR。
- 在直播的比赛中(指 2019 年 1 月 25 日这一场),MaNa 打败了使用屏幕界面的 AlphaStar 的、只训练了 7 天的原型机。
- “我们希望在不久的将来能够评估完全训练过的、使用屏幕界面的 AlphaStar。”DeepMind 似乎有计划用这台更接近人类处理方式的 AlphaStar(APM 暂且不论),来正式举行一个和真正世界顶级职业选手对抗的比赛。